Extensions
Overview
Extensions are modular components that add functionality to Jan. Each extension is designed to handle specific features.
Extensions can be managed through Settings () > Extensions:
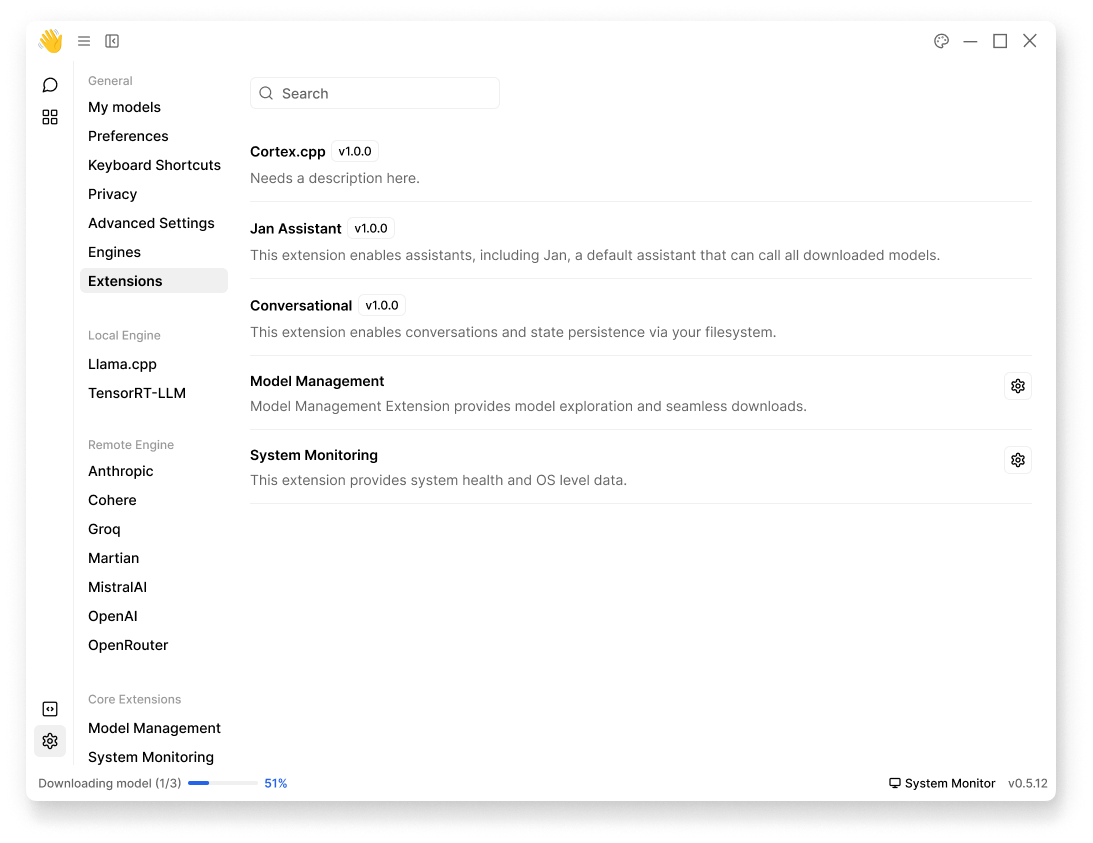
Core Extensions
Cortex.cpp
The primary extension that manages both local and remote engines capabilities:
Local Engines
- llama.cpp: Fast, efficient local inference engine that runs GGUF models directly on your device. Powers Jan's default local AI capabilities with support for multiple hardware configurations.
- TensorRT-LLM: GPU-accelerated inference engine optimized for LLMs on NVIDIA GPUs, offering high-performance and low latency for transformer-based models.
Remote Engines
- Anthropic: Access Claude models
- Cohere: Access Cohere's models
- Groq: High-performance inference
- Martian: Specialized model access
- MistralAI: Access Mistral models
- NVIDIA NIM (NVIDIA Inference Microservices): Platform for deploying and serving GPU-accelerated AI models, providing enterprise-grade reliability and scalability.
- OpenAI: Access GPT models
- OpenRouter: Multi-provider model access
- Triton-TRT-LLM: High-performance inference backend using NVIDIA Triton Inference Server with TensorRT-LLM optimization, designed for large-scale model deployment.
Jan Assistant
Enables assistants functionality, including Jan - the default assistant that can utilize all downloaded models. This extension manages:
- Default assistant configurations
- Model selection
- Conversation management
Conversational
Manages all chat-related functionality and data persistence:
Model Management
Provides model exploration and seamless downloads:
- Model discovery and browsing
- Version control & configuration handling
- Download management
System Monitoring
Provides system health and OS level data:
- Hardware utilization tracking
- Performance monitoring
- Error logging